Efficient Query Parallelism in Cortex with Dynamic Query Splitting
Categories:
Introduction
Cortex traditionally relied on static query splitting and static vertical sharding to optimize the execution of long-range PromQL queries. Static query splitting divides a query into fixed time intervals, while vertical sharding—when applicable—splits the query across subsets of time series. These techniques offered improved parallelism and reduced query latency but were limited by their one-size-fits-all approach. They did not account for differences in query range, lookback behavior, and cardinality—leading to inefficiencies like over-sharding, redundant data fetches, and storage pressure in large or complex queries.
To address those gaps, Cortex introduced dynamic query splitting and dynamic vertical sharding—two adaptive mechanisms that intelligently adjust how queries are broken down based on query semantics.
This article explores the motivations behind this evolution, how the dynamic model works, and how to configure it for more efficient scalable PromQL query execution.
Query Splitting
Query splitting breaks a single long-range query into smaller subqueries based on a configured time interval. For example, given this configuration, a 30-day range query will be split into 30 individual 1-day subqueries:
query_range:
split_queries_by_interval: 24h
These subqueries are processed in parallel by different queriers, and the results are merged at query-frontend before returning to client. This improved performance for long range queries and helped prevent timeouts and resource exhaustion.
Vertical Sharding
Unlike query splitting, which divides a query over time intervals, vertical sharding divides a query across shards of the time series data itself. Each shard processes only a portion of the matched series, reducing memory usage and computational load per querier. This is especially useful for high-cardinality queries where the number of series can reach hundreds of thousands or more.
limits:
query_vertical_shard_size: 4
For example, suppose the label selector in the following query http_requests_total{job="api"} matches 500,000 distinct time series, each corresponding to different combinations of labels like instance, path, status, and method.
sum(rate(http_requests_total{job="api"}[5m])) by (instance)
Without vertical sharding, a single querier must fetch and aggregate all 500,000 series. With vertical sharding enabled and configured to 4, the query would be split into 4 shards each processing ~125,000 series. The results are finally merged at query frontend before returning to client.
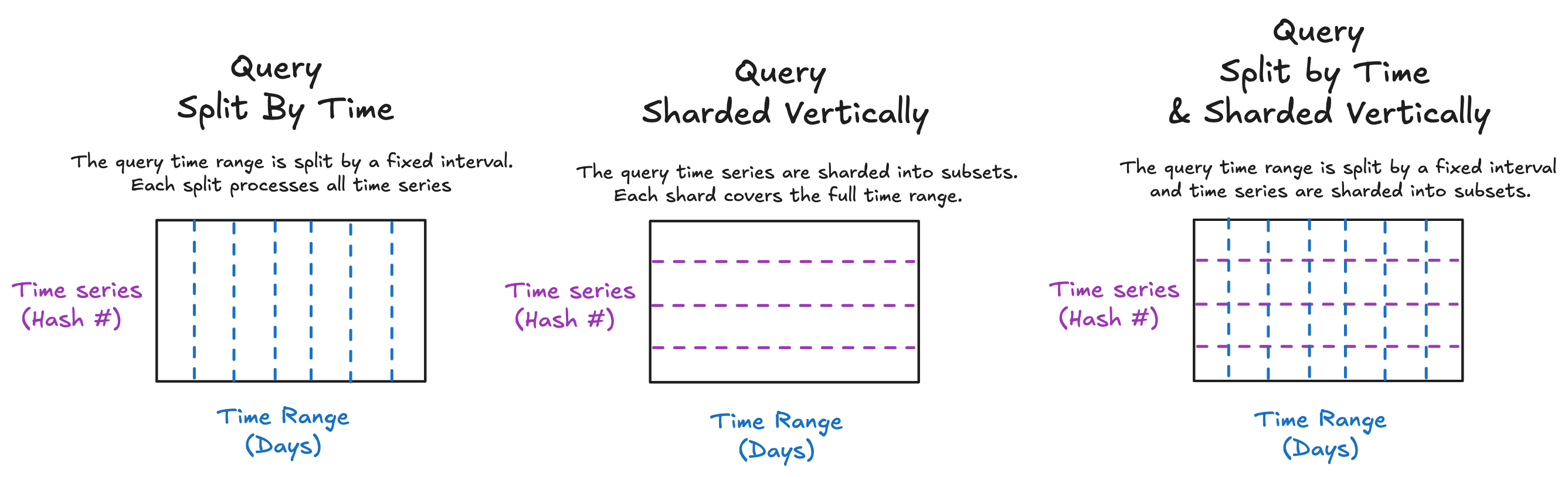
Introducing Dynamic Query Splitting
Cortex dynamic query splitting was introduced to address the limitations of static configurations. Instead of applying a fixed split interval uniformly across all queries, the dynamic logic computes an optimal split interval per query—as a multiple of the configured base interval—based on query semantics and configurable constraints. If dynamic vertical sharding is also enabled, then both split interval and vertical shard size will be dynamically adjusted for every query.
The goal is to maximize query parallelism through both horizontal splitting and vertical sharding, while staying within safe and configurable limits that prevent system overload or inefficiency. This is best explained by how dynamic splitting solves two problems:
1. Queuing and Merge Bottlenecks from Over-Splitting
While increasing parallelism through splitting and sharding is generally beneficial, it becomes counterproductive when the number of subqueries or shards far exceeds the number of available queriers.
The number of splits when using a fixed interval increases with the query’s time range, which is under the user’s control. For example:
- With a static split interval of 24 hours, a 7-day query results in 7 horizontal splits
- If the user increased query range to 100 days, the query is split into 100 horizontal splits.
- If vertical sharding is also enabled and configured to use 5 shards (
query_vertical_shard_size: 5), each split is further divided—leading to a total of 500 individual shards.
When the number of shards grows too large:
- Backend workers become saturated, causing subqueries to queue and increasing total latency.
- The query-frontend merges hundreds of partial results, which introduces overhead that can outweigh the benefits of parallelism.
- Overall system throughput degrades, especially when multiple large queries are executed concurrently.
To solve this issue, a new configuration max_shards_per_query is introduced for the maximum parallelism per query. Given the same example above:
- With a static split interval of 24 hours and
max_shards_per_queryset to 75, a 7-day query still results in 7 splits. - If the user increased query range to 100 days, the dynamic splitting algorithm will adjust the split interval to be 48 hours, producing 50 horizontal splits—keeping the total within the target of 75 shards.
- If vertical sharding is enabled and configured to use up to 5 shards, the dynamic logic selects the optimal combination of split interval and vertical shards to maximize parallelism without exceeding 75 shards.
- In this case, a 96-hour (4-day) split interval with 3 vertical shards yields exactly 75 total shards—the most efficient combination.
- Note:
enable_dynamic_vertical_shardingmust be set to true; otherwise, only the split interval will be adjusted.
In summary, with dynamic splitting enabled, you can define a target total number of shards, and Cortex will automatically adjust time splitting and vertical sharding to maximize parallelism without crossing that limit.
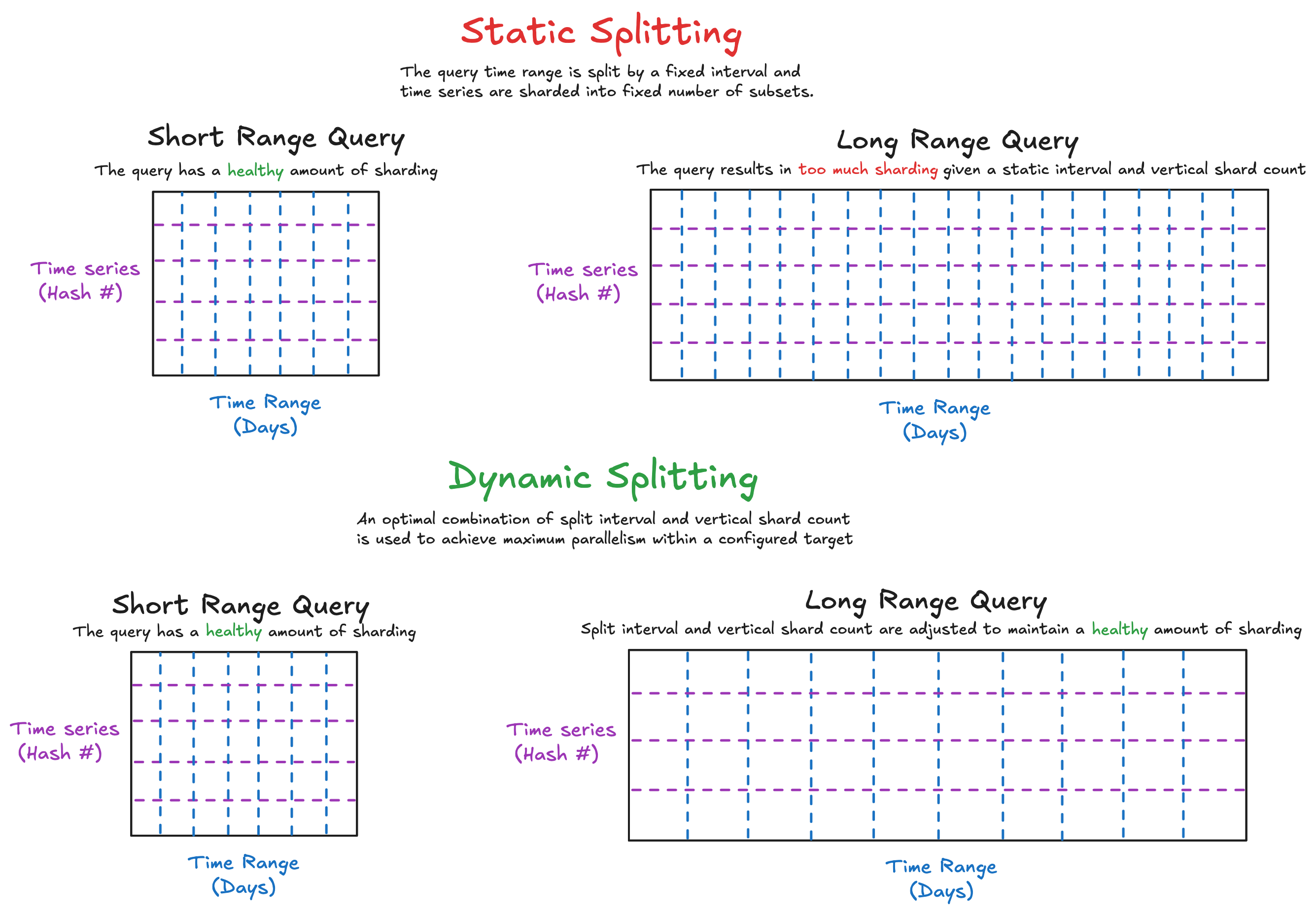
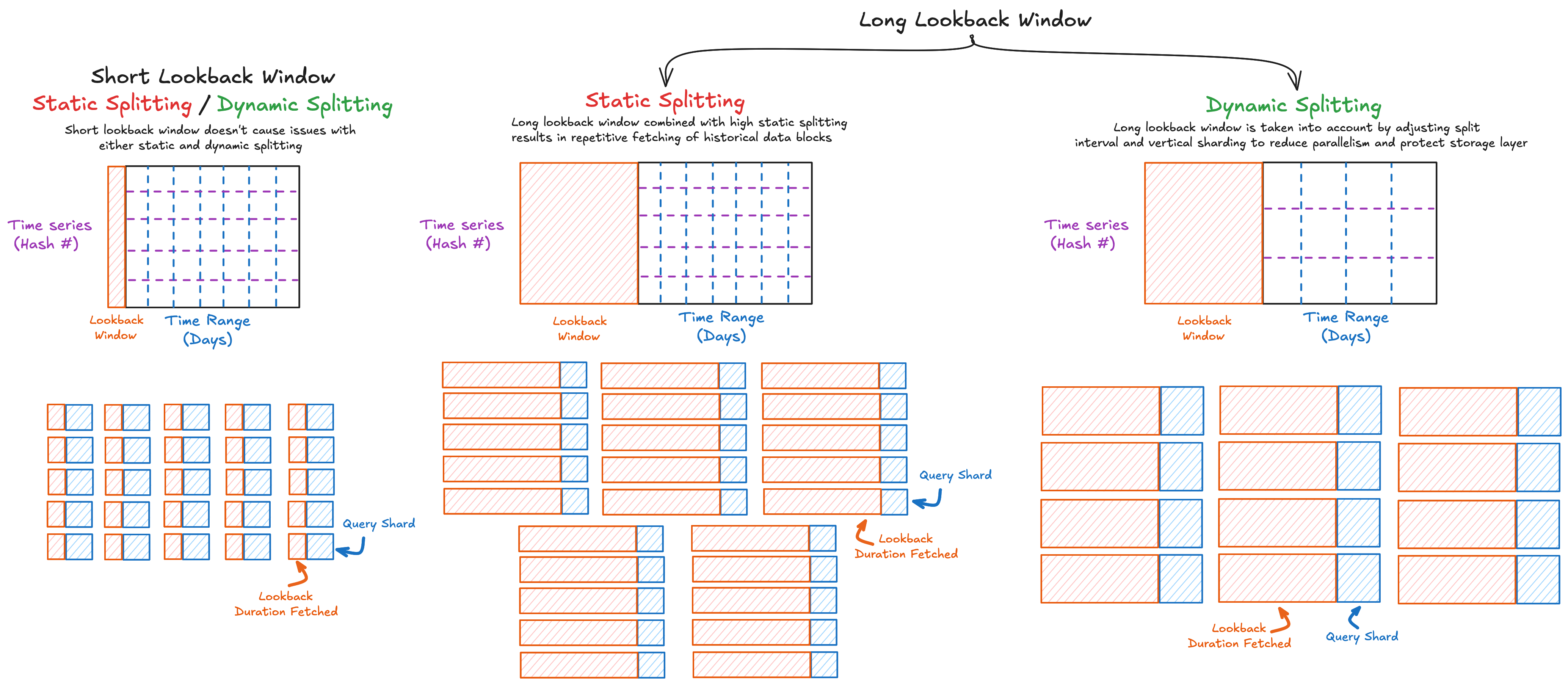
2. Parallelism Cost with Query Lookback
In PromQL, some functions like rate(), increase(), or max_over_time() use a lookback window, meaning each query must fetch samples from before the evaluation timestamp to execute.
Consider the following query that calculates the maximum container memory usage over a 90-day lookback window:
max_over_time(container_memory_usage_bytes{cluster="prod", namespace="payments"}[90d])
Suppose this query is evaluated over a 30-day range and static query splitting is configured to split it into 1-day intervals. This produces 30 subqueries, each corresponding to a single day. However, due to the [90d] range vector:
- Each subquery must fetch the full 90 days of historical data to evaluate correctly.
- The same data blocks are repeatedly fetched across all subqueries
- The total duration of data fetched is
query range + (lookback window x total shards), which results in 30 + 90 x 30 = 2,730 days.
As a result, store-gateways must handle a large amount of mostly redundant reads, repeatedly fetching data blocks for each subquery. This puts additional pressure on the storage layer, and the cumulative effect slows down query execution and degrades overall system performance. In this case, splitting the query further doesn’t reduce backend load—it amplifies it.
With dynamic splitting, you can define a target max_fetched_data_duration_per_query—the maximum cumulative duration of historical data that a single query is allowed to fetch. If the lookback window is long, the algorithm automatically increases the split interval or reduces the vertical shard size to lower the shard count and protect the storage layer.
For example, with max_fetched_data_duration_per_query set to 500d:
- A larger split interval of 120-hour (5-day) is used to split the query into 5 splits.
- This is the optimal split interval that results in highest parallelism without crossing the limit of 500 days fetched.
- The total duration fetched from storage layer becomes 30 + 90 x 5 = 480 days—lower than the target of 500 days.
How to Configure Dynamic Query Splitting
Dynamic query splitting is configured under the dynamic_query_splits section in the query_range block of Cortex’s configuration. Keep in mind that it works in conjunction with static split_queries_by_interval and query_vertical_shard_size which are required to be configured as well:
Dynamic query splitting considers the following configurations:
max_shards_per_query:Defines the maximum number of total shards (horizontal splits × vertical shards) that a single query can generate. Ifenable_dynamic_vertical_shardingis set, the dynamic logic will adjust both the split interval and vertical shard size to find the most effective combination that results in the highest degree of sharding without exceeding this limit.max_fetched_data_duration_per_query:Sets a target for the maximum total time duration of data that can be fetched across all subqueries. To keep the duration fetched below this target, a larger split interval and/or less vertical sharding is used. This is especially important for queries with long lookback windows, where excessive splitting can lead to redundant block reads, putting pressure on store-gateways and the storage layer.enable_dynamic_vertical_sharding:When enabled, vertical sharding becomes dynamic per query. Instead of using a fixed shard count, an optimal vertical shard size ranging from 1 (no sharding) to the tenant’s configuredquery_vertical_shard_sizewill be used.
Example Configuration
Let’s explore how two different queries will be handled given the following configuration:
query_range:
split_queries_by_interval: 24h
dynamic_query_splits:
max_shards_per_query: 100
max_fetched_data_duration_per_query: 8760h # 365 day
enable_dynamic_vertical_sharding: true
limits:
query_vertical_shard_size: 4
Query #1
sum by (pod) (
rate(container_cpu_usage_seconds_total{namespace="prod"}[1m])
)
- Query time range: 60 days
- Lookback window: 1 minute
Since the query has a short lookback window of 1 min, the total duration of data fetched by each shard is not going to be limiting factor. The limiting factor to consider here is maintaining less than 100 total shards. Both dynamic splitting and dynamic vertical sharding are enabled. Cortex finds the most optimal combination that results in the highest number of shards below 100. In this case:
- Number of splits by time: 30 (2 day interval)
- Vertical shard size: 3
- Total shards: 90
Query #2
sum by (pod) (
max_over_time(container_memory_usage_bytes{namespace="prod"}[30d])
)
- Query time range: 14 days
- Lookback window: 30 days
This query can be split into 14 splits and sharded vertically by 4 resulting in a total of 56 shards, which is below the limit of 100 total shards. However, since each shard is going to have to fetch all 30 days of the lookback window to evaluate in addition to the interval itself, this would result in 56 shards each fetching 31 days of data for a total of 1736 days. This is not optimal and will cause a heavy load on the backend storage layer.
Luckily we configured max_fetched_data_duration_per_query to be 365 days. This will limit query sharding to achieve highest parallelism without crossing the duration fetched limit. In this case:
- Number of splits by time: 5 (3 day interval)
- Vertical shard size: 2
- Total shards: 10
The total duration of data fetched for query evaluation is calculated using (interval + lookback window) x total shards. In this case (3 + 30) x 10 = 330 days fetched, which is below our limit of 365 days.
Conclusion
Dynamic query splitting and vertical sharding make Cortex smarter about how it executes PromQL queries. By adapting to each query’s semantics and backend constraints, Cortex avoids the limitations of static configurations—enabling efficient parallelism across diverse query patterns and consistently delivering high performance at scale.