Query Priority in Cortex
Categories:
Introduction
In high-scale monitoring environments, not all queries are created equal. Some queries power critical dashboards that need sub-second response times, while others are exploratory analytics that can tolerate delays. However, the queries from a tenant is handled FIFO (first-in-first-out), which could lead to a noisy-neighbor problem within the user.
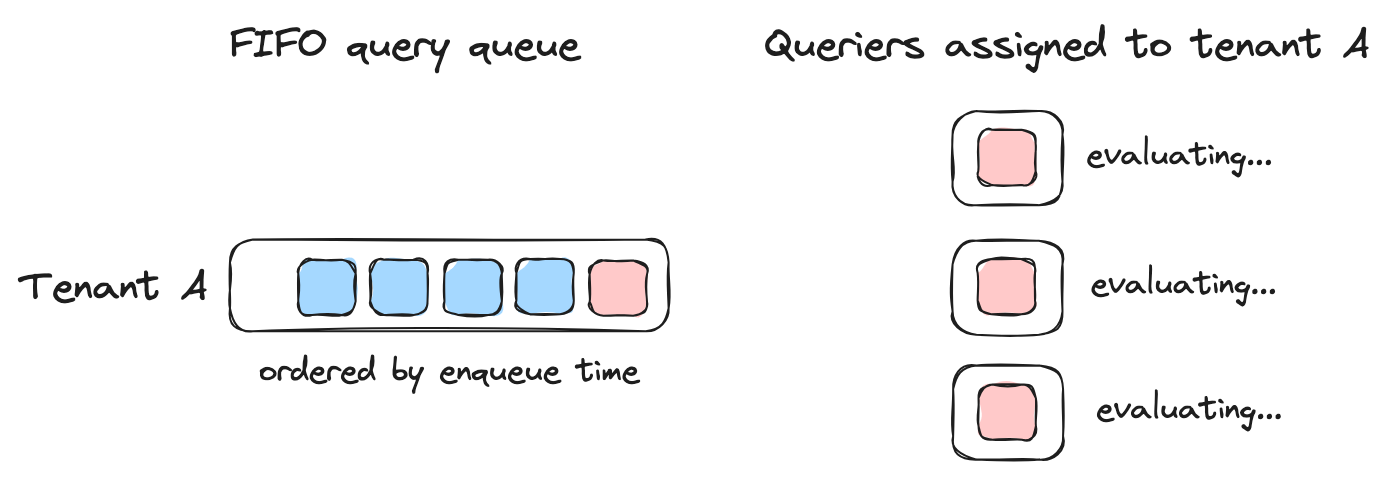
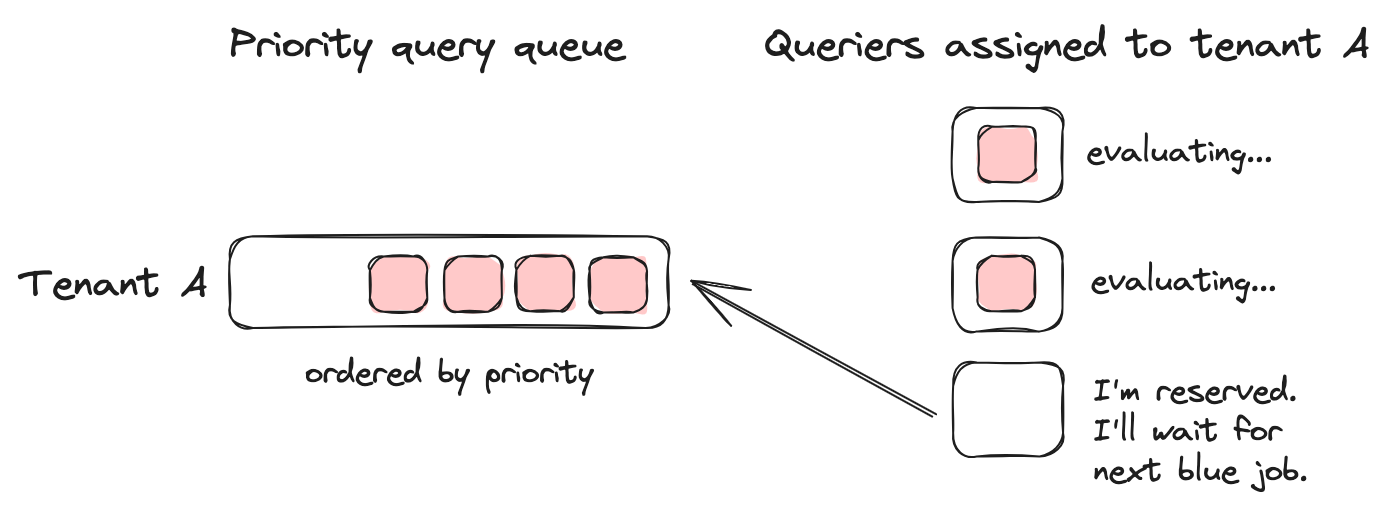
Cortex’s query priority feature addresses this challenge by allowing operators to reserve querier resources for high-priority queries.
What is Query Priority?
Query priority in Cortex enables you to classify queries based on various attributes and allocate dedicated querier resources to different priority levels. The system works by:
- Matching queries against configurable attributes (regex patterns, time ranges, API types, user agents, dashboard UIDs)
- Assigning priority levels to matched queries
- Reserving querier capacity as a percentage for each priority level
Configuration Example
query_priority:
enabled: true
default_priority: 0
priorities:
- priority: 100
reserved_queriers: 0.1 # Reserve 10% of queriers
query_attributes:
- regex: ".*alert.*" # Alert queries
- priority: 50
reserved_queriers: 0.05 # Reserve 5% of queriers
query_attributes:
- api_type: "query_range"
time_range_limit:
max: "1h" # Dashboard queries (short range)
user_agent_regex: "Grafana.*"
Benefits
1. Preventing Resource Starvation
The most compelling use case is protecting critical queries from resource-hungry analytical workloads. Without priority, a few expensive queries scanning months of data can starve dashboard queries, causing user-facing alerts to timeout.
2. SLA Differentiation
Organizations can offer different service levels:
- Tier 1: Real-time dashboards and alerts (high priority)
- Tier 2: Business intelligence queries (medium priority)
- Tier 3: Ad-hoc exploration and data exports (low priority)
Drawbacks
1. Resource Underutilization
Reserved queriers sit idle when high-priority queries aren’t running. If you reserve 30% capacity for dashboard queries that only use 10% during off-peak hours, you’re wasting 20% of your infrastructure.
2. Configuration Complexity
Query attributes require careful tuning:
- Regex patterns can be brittle and hard to maintain
- Time window matching needs constant adjustment as usage patterns evolve
- Dashboard UID matching breaks when dashboards are recreated
Best Practices
When to use query priority
- High query volume with mixed workload types
- Clear SLA requirements that justify the complexity
- Stable query patterns that won’t require frequent reconfiguration
When to avoid it:
- Homogeneous workloads where all queries have similar requirements
- Unstable environments where query patterns change frequently
Conclusion
If your users have different SLA requirements depending on their query patterns that’s consistent, this is a power feature that helps towards meeting expected availability and performance for queries. There is also plenty of room for this logic to be improved in the future, such that it self-adapts to the query pattern of the users and dynamically assign priorities to balance SLAs with fairness across different query patterns.