Blocks Storage
The blocks storage is a Cortex storage engine based on Prometheus TSDB: it stores each tenant’s time series into their own TSDB which write out their series to a on-disk block (defaults to 2h block range periods). Each block is composed by chunk files - containing the timestamp-value pairs for multiple series - and an index, which indexes metric names and labels to time series in the chunk files.
The supported backends for the blocks storage are:
- Amazon S3
- Google Cloud Storage
- Microsoft Azure Storage
- OpenStack Swift
- Local Filesystem (single node only)
Internally, some components are based on Thanos, but no Thanos knowledge is required in order to run it.
Architecture
When running the Cortex blocks storage, the Cortex architecture doesn’t significantly change and thus the general architecture documentation applies to the blocks storage as well. However, there are two additional Cortex services when running the blocks storage:
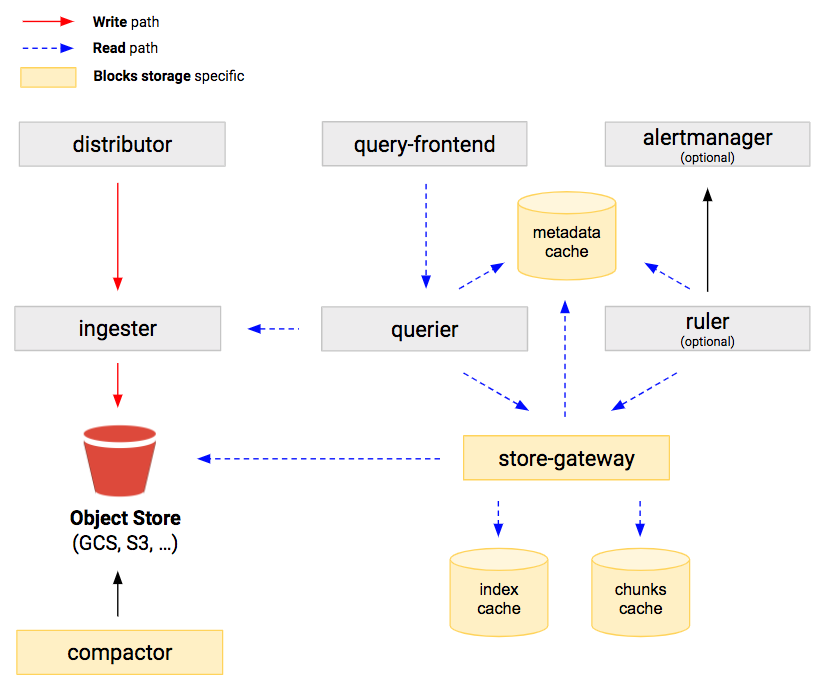
The store-gateway is responsible to query blocks and is used by the querier at query time. The store-gateway is required when running the blocks storage.
The compactor is responsible to merge and deduplicate smaller blocks into larger ones, in order to reduce the number of blocks stored in the long-term storage for a given tenant and query them more efficiently. It also keeps the bucket index updated and, for this reason, it’s a required component.
The alertmanager and ruler components can also use object storage to store its configurations and rules uploaded by users. In that case a separate bucket should be created to store alertmanager configurations and rules: using the same bucket between ruler/alertmanager and blocks will cause issue with the compactor.
The write path
Ingesters receive incoming samples from the distributors. Each push request belongs to a tenant, and the ingester appends the received samples to the specific per-tenant TSDB stored on the local disk. The received samples are both kept in-memory and written to a write-ahead log (WAL) and used to recover the in-memory series in case the ingester abruptly terminates. The per-tenant TSDB is lazily created in each ingester as soon as the first samples are received for that tenant.
The in-memory samples are periodically flushed to disk - and the WAL truncated - when a new TSDB block is created, which by default occurs every 2 hours. Each newly created block is then uploaded to the long-term storage and kept in the ingester until the configured -blocks-storage.tsdb.retention-period expires, in order to give queriers and store-gateways enough time to discover the new block on the storage and download its index-header.
In order to effectively use the WAL and being able to recover the in-memory series upon ingester abruptly termination, the WAL needs to be stored to a persistent disk which can survive in the event of an ingester failure (ie. AWS EBS volume or GCP persistent disk when running in the cloud). For example, if you’re running the Cortex cluster in Kubernetes, you may use a StatefulSet with a persistent volume claim for the ingesters. The location on the filesystem where the WAL is stored is the same where local TSDB blocks (compacted from head) are stored and cannot be decoupled. See also the timeline of block uploads and disk space estimate.
Distributor series sharding and replication
The series sharding and replication done by the distributor doesn’t change based on the storage engine.
It’s important to note that due to the replication factor N (typically 3), each time series is stored by N ingesters. Since each ingester writes its own block to the long-term storage, this leads a storage utilization N times more. Compactor solves this problem by merging blocks from multiple ingesters into a single block, and removing duplicated samples. After blocks compaction, the storage utilization is significantly smaller.
For more information, please refer to the following dedicated sections:
The read path
Queriers and store-gateways periodically iterate over the storage bucket to discover blocks recently uploaded by ingesters.
For each discovered block, queriers only download the block’s meta.json file (containing some metadata including min and max timestamp of samples within the block), while store-gateways download the meta.json as well as the index-header, which is a small subset of the block’s index used by the store-gateway to lookup series at query time.
Queriers use the blocks metadata to compute the list of blocks that need to be queried at query time and fetch matching series from the store-gateway instances holding the required blocks.
For more information, please refer to the following dedicated sections:
Known issues
GitHub issues tagged with the storage/blocks label are the best source of currently known issues affecting the blocks storage.