Compactor
The compactor is an service which is responsible to:
- Compact multiple blocks of a given tenant into a single optimized larger block. This helps to reduce storage costs (deduplication, index size reduction), and increase query speed (querying fewer blocks is faster).
- Keep the per-tenant bucket index updated. The bucket index is used by queriers, store-gateways and rulers to discover new blocks in the storage.
The compactor is stateless.
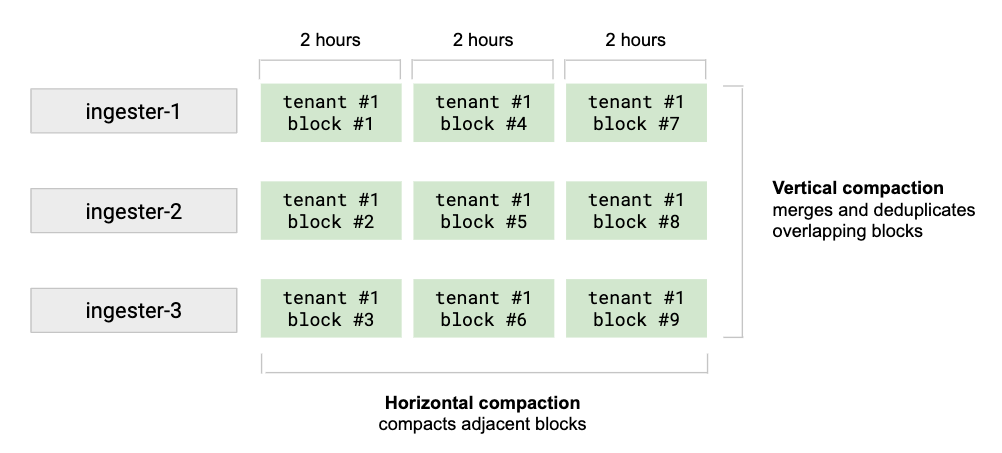
How compaction works
The blocks compaction has two main benefits:
- Vertically compact blocks uploaded by all ingesters for the same time range
- Horizontally compact blocks with small time ranges into a single larger block
The vertical compaction merges all the blocks of a tenant uploaded by ingesters for the same time range (2 hours ranges by default) into a single block, while de-duplicating samples that are originally written to N blocks as a result of replication. This step reduces number of blocks for single 2 hours time range from #(number of ingesters) to 1 per tenant.
The horizontal compaction triggers after the vertical compaction and compacts several blocks with adjacent 2-hour range periods into a single larger block. Even though the total size of block chunks doesn’t change after this compaction, it may still significantly reduce the size of the index and the index-header kept in memory by store-gateways.
Compactor sharding
The compactor optionally supports sharding.
When sharding is enabled, multiple compactor instances can coordinate to split the workload and shard blocks by tenant. All the blocks of a tenant are processed by a single compactor instance at any given time, but compaction for different tenants may simultaneously run on different compactor instances.
Whenever the pool of compactors increase or decrease (ie. following up a scale up/down), tenants are resharded across the available compactor instances without any manual intervention.
The compactor sharding is based on the Cortex hash ring. At startup, a compactor generates random tokens and registers itself to the ring. While running, it periodically scans the storage bucket (every -compactor.compaction-interval) to discover the list of tenants in the storage and compacts blocks for each tenant whose hash matches the token ranges assigned to the instance itself within the ring.
This feature can be enabled via -compactor.sharding-enabled=true and requires the backend hash ring to be configured via -compactor.ring.* flags (or their respective YAML config options).
Waiting for stable ring at startup
In the event of a cluster cold start or scale up of 2+ compactor instances at the same time we may end up in a situation where each new compactor instance starts at a slightly different time and thus each one runs the first compaction based on a different state of the ring. This is not a critical condition, but may be inefficient, because multiple compactor replicas may start compacting the same tenant nearly at the same time.
To reduce the likelihood this could happen, the compactor waits for a stable ring at startup. A ring is considered stable if no instance is added/removed to the ring for at least -compactor.ring.wait-stability-min-duration. If the ring keep getting changed after -compactor.ring.wait-stability-max-duration, the compactor will stop waiting for a stable ring and will proceed starting up normally.
To disable this waiting logic, you can start the compactor with -compactor.ring.wait-stability-min-duration=0.
Soft and hard blocks deletion
When the compactor successfully compacts some source blocks into a larger block, source blocks are deleted from the storage. Blocks deletion is not immediate, but follows a two steps process:
- First, a block is marked for deletion (soft delete)
- Then, once a block is marked for deletion for longer then
-compactor.deletion-delay, the block is deleted from the storage (hard delete)
The compactor is both responsible to mark blocks for deletion and then hard delete them once the deletion delay expires.
The soft deletion is based on a tiny deletion-mark.json file stored within the block location in the bucket which gets looked up both by queriers and store-gateways.
This soft deletion mechanism is used to give enough time to queriers and store-gateways to discover the new compacted blocks before the old source blocks are deleted. If source blocks would be immediately hard deleted by the compactor, some queries involving the compacted blocks may fail until the queriers and store-gateways haven’t rescanned the bucket and found both deleted source blocks and the new compacted ones.
Compactor disk utilization
The compactor needs to download source blocks from the bucket to the local disk, and store the compacted block to the local disk before uploading it to the bucket. Depending on the largest tenants in your cluster and the configured -compactor.block-ranges, the compactor may need a lot of disk space.
Assuming max_compaction_range_blocks_size is the total size of blocks for the largest tenant (you can measure it inspecting the bucket) and the longest -compactor.block-ranges period, the formula to estimate the minimum disk space required is:
min_disk_space_required = compactor.compaction-concurrency * max_compaction_range_blocks_size * 2
Alternatively, assuming the largest -compactor.block-ranges is 24h (default), you could consider 150GB of disk space every 10M active series owned by the largest tenant. For example, if your largest tenant has 30M active series and -compactor.compaction-concurrency=1 we would recommend having a disk with at least 450GB available.
Compactor HTTP endpoints
GET /compactor/ring
Displays the status of the compactors ring, including the tokens owned by each compactor and an option to remove (forget) instances from the ring.
Compactor configuration
This section described the compactor configuration. For the general Cortex configuration and references to common config blocks, please refer to the configuration documentation.
compactor_config
The compactor_config configures the compactor for the blocks storage.
compactor:
# List of compaction time ranges.
# CLI flag: -compactor.block-ranges
[block_ranges: <list of duration> | default = 2h0m0s,12h0m0s,24h0m0s]
# Number of Go routines to use when syncing block index and chunks files from
# the long term storage.
# CLI flag: -compactor.block-sync-concurrency
[block_sync_concurrency: <int> | default = 20]
# Number of Go routines to use when syncing block meta files from the long
# term storage.
# CLI flag: -compactor.meta-sync-concurrency
[meta_sync_concurrency: <int> | default = 20]
# Minimum age of fresh (non-compacted) blocks before they are being processed.
# Malformed blocks older than the maximum of consistency-delay and 48h0m0s
# will be removed.
# CLI flag: -compactor.consistency-delay
[consistency_delay: <duration> | default = 0s]
# Data directory in which to cache blocks and process compactions
# CLI flag: -compactor.data-dir
[data_dir: <string> | default = "./data"]
# The frequency at which the compaction runs
# CLI flag: -compactor.compaction-interval
[compaction_interval: <duration> | default = 1h]
# How many times to retry a failed compaction within a single compaction run.
# CLI flag: -compactor.compaction-retries
[compaction_retries: <int> | default = 3]
# Max number of concurrent compactions running.
# CLI flag: -compactor.compaction-concurrency
[compaction_concurrency: <int> | default = 1]
# How frequently compactor should run blocks cleanup and maintenance, as well
# as update the bucket index.
# CLI flag: -compactor.cleanup-interval
[cleanup_interval: <duration> | default = 15m]
# Max number of tenants for which blocks cleanup and maintenance should run
# concurrently.
# CLI flag: -compactor.cleanup-concurrency
[cleanup_concurrency: <int> | default = 20]
# Time before a block marked for deletion is deleted from bucket. If not 0,
# blocks will be marked for deletion and compactor component will permanently
# delete blocks marked for deletion from the bucket. If 0, blocks will be
# deleted straight away. Note that deleting blocks immediately can cause query
# failures.
# CLI flag: -compactor.deletion-delay
[deletion_delay: <duration> | default = 12h]
# For tenants marked for deletion, this is time between deleting of last
# block, and doing final cleanup (marker files, debug files) of the tenant.
# CLI flag: -compactor.tenant-cleanup-delay
[tenant_cleanup_delay: <duration> | default = 6h]
# When enabled, mark blocks containing index with out-of-order chunks for no
# compact instead of halting the compaction.
# CLI flag: -compactor.skip-blocks-with-out-of-order-chunks-enabled
[skip_blocks_with_out_of_order_chunks_enabled: <boolean> | default = false]
# Number of goroutines to use when fetching/uploading block files from object
# storage.
# CLI flag: -compactor.block-files-concurrency
[block_files_concurrency: <int> | default = 10]
# Number of goroutines to use when fetching blocks from object storage when
# compacting.
# CLI flag: -compactor.blocks-fetch-concurrency
[blocks_fetch_concurrency: <int> | default = 3]
# When enabled, at compactor startup the bucket will be scanned and all found
# deletion marks inside the block location will be copied to the markers
# global location too. This option can (and should) be safely disabled as soon
# as the compactor has successfully run at least once.
# CLI flag: -compactor.block-deletion-marks-migration-enabled
[block_deletion_marks_migration_enabled: <boolean> | default = false]
# Comma separated list of tenants that can be compacted. If specified, only
# these tenants will be compacted by compactor, otherwise all tenants can be
# compacted. Subject to sharding.
# CLI flag: -compactor.enabled-tenants
[enabled_tenants: <string> | default = ""]
# Comma separated list of tenants that cannot be compacted by this compactor.
# If specified, and compactor would normally pick given tenant for compaction
# (via -compactor.enabled-tenants or sharding), it will be ignored instead.
# CLI flag: -compactor.disabled-tenants
[disabled_tenants: <string> | default = ""]
# Shard tenants across multiple compactor instances. Sharding is required if
# you run multiple compactor instances, in order to coordinate compactions and
# avoid race conditions leading to the same tenant blocks simultaneously
# compacted by different instances.
# CLI flag: -compactor.sharding-enabled
[sharding_enabled: <boolean> | default = false]
# The sharding strategy to use. Supported values are: default,
# shuffle-sharding.
# CLI flag: -compactor.sharding-strategy
[sharding_strategy: <string> | default = "default"]
sharding_ring:
kvstore:
# Backend storage to use for the ring. Supported values are: consul,
# dynamodb, etcd, inmemory, memberlist, multi.
# CLI flag: -compactor.ring.store
[store: <string> | default = "consul"]
# The prefix for the keys in the store. Should end with a /.
# CLI flag: -compactor.ring.prefix
[prefix: <string> | default = "collectors/"]
# The consul_config configures the consul client.
# The CLI flags prefix for this block config is: compactor.ring
[consul: <consul_config>]
dynamodb:
# Region to access dynamodb.
# CLI flag: -compactor.ring.dynamodb.region
[region: <string> | default = ""]
# Table name to use on dynamodb.
# CLI flag: -compactor.ring.dynamodb.table-name
[table_name: <string> | default = ""]
# Time to expire items on dynamodb.
# CLI flag: -compactor.ring.dynamodb.ttl-time
[ttl: <duration> | default = 0s]
# Time to refresh local ring with information on dynamodb.
# CLI flag: -compactor.ring.dynamodb.puller-sync-time
[puller_sync_time: <duration> | default = 1m]
# Maximum number of retries for DDB KV CAS.
# CLI flag: -compactor.ring.dynamodb.max-cas-retries
[max_cas_retries: <int> | default = 10]
# Timeout of dynamoDbClient requests. Default is 2m.
# CLI flag: -compactor.ring.dynamodb.timeout
[timeout: <duration> | default = 2m]
# The etcd_config configures the etcd client.
# The CLI flags prefix for this block config is: compactor.ring
[etcd: <etcd_config>]
multi:
# Primary backend storage used by multi-client.
# CLI flag: -compactor.ring.multi.primary
[primary: <string> | default = ""]
# Secondary backend storage used by multi-client.
# CLI flag: -compactor.ring.multi.secondary
[secondary: <string> | default = ""]
# Mirror writes to secondary store.
# CLI flag: -compactor.ring.multi.mirror-enabled
[mirror_enabled: <boolean> | default = false]
# Timeout for storing value to secondary store.
# CLI flag: -compactor.ring.multi.mirror-timeout
[mirror_timeout: <duration> | default = 2s]
# Period at which to heartbeat to the ring. 0 = disabled.
# CLI flag: -compactor.ring.heartbeat-period
[heartbeat_period: <duration> | default = 5s]
# The heartbeat timeout after which compactors are considered unhealthy
# within the ring. 0 = never (timeout disabled).
# CLI flag: -compactor.ring.heartbeat-timeout
[heartbeat_timeout: <duration> | default = 1m]
# Time since last heartbeat before compactor will be removed from ring. 0 to
# disable
# CLI flag: -compactor.auto-forget-delay
[auto_forget_delay: <duration> | default = 2m]
# Set to true to enable ring detailed metrics. These metrics provide
# detailed information, such as token count and ownership per tenant.
# Disabling them can significantly decrease the number of metrics emitted.
# CLI flag: -compactor.ring.detailed-metrics-enabled
[detailed_metrics_enabled: <boolean> | default = true]
# Minimum time to wait for ring stability at startup. 0 to disable.
# CLI flag: -compactor.ring.wait-stability-min-duration
[wait_stability_min_duration: <duration> | default = 1m]
# Maximum time to wait for ring stability at startup. If the compactor ring
# keeps changing after this period of time, the compactor will start anyway.
# CLI flag: -compactor.ring.wait-stability-max-duration
[wait_stability_max_duration: <duration> | default = 5m]
# Name of network interface to read address from.
# CLI flag: -compactor.ring.instance-interface-names
[instance_interface_names: <list of string> | default = [eth0 en0]]
# File path where tokens are stored. If empty, tokens are not stored at
# shutdown and restored at startup.
# CLI flag: -compactor.ring.tokens-file-path
[tokens_file_path: <string> | default = ""]
# Unregister the compactor during shutdown if true.
# CLI flag: -compactor.ring.unregister-on-shutdown
[unregister_on_shutdown: <boolean> | default = true]
# Timeout for waiting on compactor to become ACTIVE in the ring.
# CLI flag: -compactor.ring.wait-active-instance-timeout
[wait_active_instance_timeout: <duration> | default = 10m]
# How long shuffle sharding planner would wait before running planning code.
# This delay would prevent double compaction when two compactors claimed same
# partition in grouper at same time.
# CLI flag: -compactor.sharding-planner-delay
[sharding_planner_delay: <duration> | default = 10s]
# The compaction strategy to use. Supported values are: default, partitioning.
# CLI flag: -compactor.compaction-strategy
[compaction_strategy: <string> | default = "default"]
# How long compaction visit marker file should be considered as expired and
# able to be picked up by compactor again.
# CLI flag: -compactor.compaction-visit-marker-timeout
[compaction_visit_marker_timeout: <duration> | default = 10m]
# How frequently compaction visit marker file should be updated duration
# compaction.
# CLI flag: -compactor.compaction-visit-marker-file-update-interval
[compaction_visit_marker_file_update_interval: <duration> | default = 1m]
# How long cleaner visit marker file should be considered as expired and able
# to be picked up by cleaner again. The value should be smaller than
# -compactor.cleanup-interval
# CLI flag: -compactor.cleaner-visit-marker-timeout
[cleaner_visit_marker_timeout: <duration> | default = 10m]
# How frequently cleaner visit marker file should be updated when cleaning
# user.
# CLI flag: -compactor.cleaner-visit-marker-file-update-interval
[cleaner_visit_marker_file_update_interval: <duration> | default = 5m]
# When enabled, index verification will ignore out of order label names.
# CLI flag: -compactor.accept-malformed-index
[accept_malformed_index: <boolean> | default = false]
# When enabled, caching bucket will be used for compactor, except cleaner
# service, which serves as the source of truth for block status
# CLI flag: -compactor.caching-bucket-enabled
[caching_bucket_enabled: <boolean> | default = false]
# When enabled, caching bucket will be used for cleaner
# CLI flag: -compactor.cleaner-caching-bucket-enabled
[cleaner_caching_bucket_enabled: <boolean> | default = false]