Production tips
This page shares some tips and things to take in consideration when setting up a production Cortex cluster based on the blocks storage.
Ingester
Ensure a high number of max open file descriptors
The ingester stores received series into per-tenant TSDB blocks. Both TSDB WAL, head and compacted blocks are composed by a relatively large number of files which gets loaded via mmap. This means that the ingester keeps file descriptors open for TSDB WAL segments, chunk files and compacted blocks which haven’t reached the retention period yet.
If your Cortex cluster has many tenants or ingester is running with a long -blocks-storage.tsdb.retention-period, the ingester may hit the file-max ulimit (maximum number of open file descriptions by a process); in such case, we recommend increasing the limit on your system or enabling shuffle sharding.
The rule of thumb is that a production system shouldn’t have the file-max ulimit below 65536, but higher values are recommended (eg. 1048576).
Ingester disk space
Ingesters create blocks on disk as samples come in, then every 2 hours (configurable) they cut off those blocks and start a new block.
We typically configure ingesters to retain these blocks for longer, to allow time to recover if something goes wrong uploading to the long-term store and to reduce work in queriers - more detail here.
If you configure ingesters with -blocks-storage.tsdb.retention-period=24h, a rule of thumb for disk space required is to take the number of timeseries after replication and multiply by 30KB.
For example, if you have 20M active series replicated 3 ways, this gives approx 1.7TB. Divide by the number of ingesters and allow some margin for growth, e.g. if you have 20 ingesters then 100GB each should work, or 150GB each to be more comfortable.
Querier
Ensure caching is enabled
The querier relies on caching to reduce the number API calls to the storage bucket. Ensure caching is properly configured and properly scaled.
Ensure bucket index is enabled
The bucket index reduces the number of API calls to the storage bucket and, when enabled, the querier is up and running immediately after the startup (no need to run an initial bucket scan). Ensure bucket index is enabled for the querier.
Avoid querying non compacted blocks
When running Cortex blocks storage cluster at scale, querying non compacted blocks may be inefficient for two reasons:
- Non compacted blocks contain duplicated samples (as effect of the ingested samples replication)
- Overhead introduced querying many small indexes
Because of this, we would suggest to avoid querying non compacted blocks. In order to do it, you should:
- Run the compactor
- Configure queriers
-querier.query-store-afterlarge enough to give compactor enough time to compact newly uploaded blocks (see below) - Configure queriers
-querier.query-ingesters-withinequal to-querier.query-store-afterplus 5m (5 minutes is just a delta to query the boundary both from ingesters and queriers) - Configure ingesters
-blocks-storage.tsdb.retention-periodat least as-querier.query-ingesters-within - Lower
-blocks-storage.bucket-store.ignore-deletion-marks-delayto 1h, otherwise non compacted blocks could be queried anyway, even if their compacted replacement is available
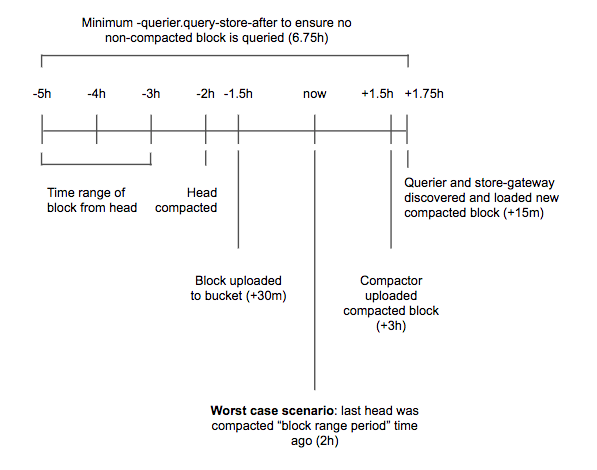
How to estimate -querier.query-store-after
The -querier.query-store-after should be set to a duration large enough to give compactor enough time to compact newly uploaded blocks, and queriers and store-gateways to discover and sync newly compacted blocks.
The following diagram shows all the timings involved in the estimation. This diagram should be used only as a template and you’re expected to tweak the assumptions based on real measurements in your Cortex cluster. In this example, the following assumptions have been done:
- An ingester takes up to 30 minutes to upload a block to the storage
- The compactor takes up to 3 hours to compact 2h blocks shipped from all ingesters
- Querier and store-gateways take up to 15 minutes to discover and load a new compacted block
Given these assumptions, in the worst case scenario it would take up to 6h and 45m since when a sample has been ingested until that sample has been appended to a block flushed to the storage and that block has been vertically compacted with all other overlapping 2h blocks shipped from ingesters.
Store-gateway
Ensure caching is enabled
The store-gateway heavily relies on caching both to speed up the queries and to reduce the number of API calls to the storage bucket. Ensure caching is properly configured and properly scaled.
Ensure bucket index is enabled
The bucket index reduces the number of API calls to the storage bucket and the startup time of the store-gateway. Ensure bucket index is enabled for the store-gateway.
Ensure a high number of max open file descriptors
The store-gateway stores each block’s index-header on the local disk and loads it via mmap. This means that the store-gateway keeps a file descriptor open for each loaded block. If your Cortex cluster has many blocks in the bucket, the store-gateway may hit the file-max ulimit (maximum number of open file descriptions by a process); in such case, we recommend increasing the limit on your system or running more store-gateway instances with blocks sharding enabled.
The rule of thumb is that a production system shouldn’t have the file-max ulimit below 65536, but higher values are recommended (eg. 1048576).
Compactor
Ensure the compactor has enough disk space
The compactor generally needs a lot of disk space in order to download source blocks from the bucket and store the compacted block before uploading it to the storage. Please refer to Compactor disk utilization for more information about how to do capacity planning.
Caching
Ensure memcached is properly scaled
The rule of thumb to ensure memcached is properly scaled is to make sure evictions happen infrequently. When that’s not the case and they affect query performances, the suggestion is to scale out the memcached cluster adding more nodes or increasing the memory limit of existing ones.
We also recommend to run a different memcached cluster for each cache type (metadata, index, chunks). It’s not required, but suggested to not worry about the effect of memory pressure on a cache type against others.
Alertmanager
Ensure Alertmanager networking is hardened
If the Alertmanager API is enabled, users with access to Cortex can autonomously configure the Alertmanager, including receiver integrations that allow to issue network requests to the configured URL (eg. webhook). If the Alertmanager network is not hardened, Cortex users may have the ability to issue network requests to any network endpoint including services running in the local network accessible by the Alertmanager itself.
Despite hardening the system is out of the scope of Cortex, Cortex provides a basic built-in firewall to block connections created by Alertmanager receiver integrations:
-alertmanager.receivers-firewall-block-cidr-networks-alertmanager.receivers-firewall-block-private-addresses
These settings can also be overridden on a per-tenant basis via overrides specified in the runtime config.