Shuffle Sharding
Cortex leverages sharding techniques to horizontally scale both single and multi-tenant clusters beyond the capacity of a single node.
Background
The default sharding strategy employed by Cortex distributes the workload across the entire pool of instances running a given service (eg. ingesters). For example, on the write path, each tenant’s series are sharded across all ingesters, regardless of how many active series the tenant has or how many different tenants are in the cluster.
The default strategy allows for a fair balance on the resources consumed by each instance (ie. CPU and memory) and to maximise these resources across the cluster.
However, in a multi-tenant cluster, this approach also introduces some downsides:
- An outage affects all tenants
- A misbehaving tenant (eg. causing out-of-memory) could affect all other tenants.
The goal of shuffle sharding is to provide an alternative sharding strategy to reduce the blast radius of an outage and better isolate tenants.
What is shuffle sharding?
Shuffle sharding is a technique used to isolate different tenants’ workloads and to give each tenant a single-tenant experience even if they’re running in a shared cluster. This technique has been publicly shared and clearly explained by AWS in their builders’ library and a reference implementation has been shown in the Route53 Infima library.
The idea is to assign each tenant a shard composed of a subset of the Cortex service instances, aiming to minimize the overlapping instances between two different tenants. Shuffle sharding brings the following benefits over the default sharding strategy:
- An outage on some Cortex cluster instances/nodes will only affect a subset of tenants.
- A misbehaving tenant will affect only its shard instances. Due to the low overlap of instances between different tenants, it’s statistically quite likely that any other tenant will run on different instances or only a subset of instances will match the affected ones.
Shuffle sharding requires no more resources than the default sharding strategy, but instances may be less evenly balanced from time to time.
Low overlapping instances probability
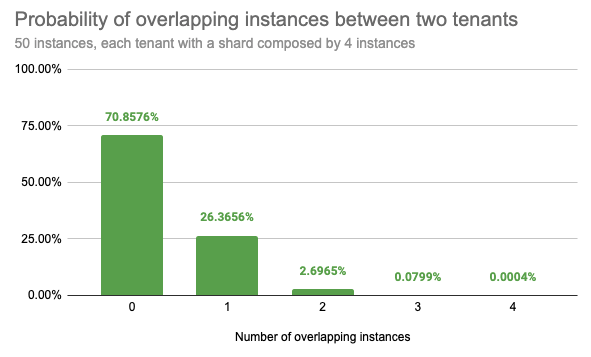
For example, given a Cortex cluster running 50 ingesters and assigning each tenant 4 out of 50 ingesters, shuffling instances between each tenant, we get 230K possible combinations.
Randomly picking two different tenants, we have the:
- 71% chance that they will not share any instance
- 26% chance that they will share only 1 instance
- 2.7% chance that they will share 2 instances
- 0.08% chance that they will share 3 instances
- Only a 0.0004% chance that their instances will fully overlap
Cortex shuffle sharding
Cortex currently supports shuffle sharding in the following services:
Shuffle sharding is disabled by default and needs to be explicitly enabled in the configuration.
Guaranteed properties
The Cortex shuffle sharding implementation guarantees the following properties:
- Stability
Given a consistent state of the hash ring, the shuffle sharding algorithm always selects the same instances for a given tenant, even across different machines. - Consistency
Adding or removing 1 instance from the hash ring leads to only 1 instance changed at most, in each tenant’s shard. - Shuffling
Probabilistically and for a large enough cluster, it ensures that every tenant gets a different set of instances, with a reduced number of overlapping instances between two tenants to improve failure isolation. - Zone-awareness
When zone-aware replication is enabled, the subset of instances selected for each tenant contains a balanced number of instances for each availability zone.
Ingesters shuffle sharding
By default, the Cortex distributor spreads the received series across all running ingesters.
When shuffle sharding is enabled for the ingesters, the distributor and ruler on the write path spread each tenant series across -distributor.ingestion-tenant-shard-size number of ingesters, while on the read path, the querier and ruler queries only the subset of ingesters holding the series for a given tenant.
The shard size can be overridden on a per-tenant basis in the limits overrides configuration.
Ingesters write path
To enable shuffle-sharding for ingesters on the write path, you need to configure the following CLI flags (or their respective YAML config options) to distributor, ingester, and ruler:
-distributor.sharding-strategy=shuffle-sharding-distributor.ingestion-tenant-shard-size=<size><size>should be set to the number of ingesters each tenant series should be sharded to. If<size>is greater than the number of available ingesters in the Cortex cluster, the tenant series are sharded across all ingesters.
Ingesters read path
Assuming shuffle-sharding has been enabled for the write path, to enable shuffle-sharding for ingesters on the read path too, you need to configure the following CLI flags (or their respective YAML config options) to querier and ruler:
-distributor.sharding-strategy=shuffle-sharding-distributor.ingestion-tenant-shard-size=<size>-querier.shuffle-sharding-ingesters-lookback-period=<period>
Queriers and rulers fetch in-memory series from the minimum set of required ingesters, selecting only ingesters which may have received series since ’now - lookback period’. The configured lookback<period>should be greater than or equal to-querier.query-store-afterand-querier.query-ingesters-withinif set, and greater than the estimated minimum time it takes for the oldest samples stored in a block uploaded by ingester to be discovered and available for querying (3h with the default configuration).
Rollout strategy
If you’re running a Cortex cluster with shuffle-sharding disabled and you want to enable it for ingesters, the following rollout strategy should be used to avoid missing querying any time-series in the ingesters’ memory:
- Enable ingesters shuffle-sharding on the write path
- Wait at least
-querier.shuffle-sharding-ingesters-lookback-periodtime - Enable ingesters shuffle-sharding on the read path
Limitation: decreasing the tenant shard size
The current shuffle-sharding implementation in Cortex has a limitation which prevents safely decreasing the tenant shard size if the ingesters shuffle-sharding is enabled on the read path.
The problem is that if a tenant’s subring decreases in size, there is currently no way for the queriers and rulers to know how big the tenant subring was previously, and hence they will potentially miss an ingester with data for that tenant. In other words, the lookback mechanism to select the ingesters which may have received series since ’now - lookback period’ doesn’t work correctly if the tenant shard size is decreased.
This is deemed an infrequent operation that we considered banning, but a workaround still exists:
- Disable shuffle-sharding on the read path
- Decrease the configured tenant shard size
- Wait at least
-querier.shuffle-sharding-ingesters-lookback-periodtime - Re-enable shuffle-sharding on the read path
Query-frontend and Query-scheduler shuffle sharding
By default, all Cortex queriers can execute received queries for a given tenant.
When shuffle sharding is enabled by setting -frontend.max-queriers-per-tenant (or its respective YAML config option) to a value higher than 0 and lower than the number of available queriers, only the specified number of queriers will execute queries for a single tenant.
Note that this distribution happens in the query-frontend, or query-scheduler if used. When using query-scheduler, the -frontend.max-queriers-per-tenant option must be set for the query-scheduler component. When not using query-frontend (with or without scheduler), this option is not available.
The maximum number of queriers can be overridden on a per-tenant basis in the limits overrides configuration.
The impact of “query of death”
In the event a tenant is repeatedly sending a “query of death” which leads the querier to crash or get killed because of out-of-memory, the crashed querier will get disconnected from the query-frontend or query-scheduler and a new querier will be immediately assigned to the tenant’s shard. This practically invalidates the assumption that shuffle-sharding can be used to contain the blast radius in case of a query of death.
To mitigate it, Cortex allows you to configure a delay between when a querier disconnects because of a crash and when the crashed querier is actually removed from the tenant’s shard (and another healthy querier is added as a replacement). A delay of 1 minute may be a reasonable trade-off:
- Query-frontend:
-query-frontend.querier-forget-delay=1m - Query-scheduler:
-query-scheduler.querier-forget-delay=1m
Store-gateway shuffle sharding
The Cortex store-gateway – used by the blocks storage – by default spreads each tenant’s blocks across all running store-gateways.
When shuffle sharding is enabled via -store-gateway.sharding-strategy=shuffle-sharding (or its respective YAML config option), each tenant’s blocks will be sharded across a subset of -store-gateway.tenant-shard-size store-gateway instances. This configuration needs to be set to store-gateway, querier, and ruler.
The shard size can be overridden on a per-tenant basis setting store_gateway_tenant_shard_size in the limits overrides configuration.
Please check out the store-gateway documentation for more information about how it works.
Ruler shuffle sharding
Cortex ruler can run in three modes:
- No sharding at all. This is the most basic mode of the ruler. It is activated by using
-ruler.enable-sharding=false(default) and works correctly only if a single ruler is running. In this mode, the Ruler loads all rules for all tenants. - Default sharding, activated by using
-ruler.enable-sharding=trueand-ruler.sharding-strategy=default(default). In this mode, rulers register themselves into the ring. Each ruler will then select and evaluate only those rules that it “owns”. - Shuffle sharding, activated by using
-ruler.enable-sharding=trueand-ruler.sharding-strategy=shuffle-sharding. Similarly to default sharding, rulers use the ring to distribute workload, but rule groups for each tenant can only be evaluated on a limited number of rulers (-ruler.tenant-shard-size, can also be set per tenant asruler_tenant_shard_sizein overrides).
Note that when using sharding strategy, each rule group is evaluated by a single ruler only; there is no replication.
Compactor shuffle sharding
Cortex compactor can run in three modes:
- No sharding at all. This is the most basic mode of the compactor. It is activated by using
-compactor.sharding-enabled=false(default). In this mode, every compactor will run every compaction. - Default sharding, activated by using
-compactor.sharding-enabled=trueand-compactor.sharding-strategy=default(default). In this mode, compactors register themselves into the ring. One single tenant will belong to only 1 compactor. - Shuffle sharding, activated by using
-compactor.sharding-enabled=trueand-compactor.sharding-strategy=shuffle-sharding. Similarly to default sharding, but compactions for each tenant can be carried out on multiple compactors (-compactor.tenant-shard-size, can also be set per tenant ascompactor_tenant_shard_sizein overrides).
With shuffle sharding selected as the sharding strategy, a subset of the compactors will be used to handle a user based on the shard size.
The idea behind using the shuffle sharding strategy for the compactor is to further enable horizontal scalability and build tolerance for compactions that may take longer than the compaction interval.
FAQ
Does shuffle sharding add additional overhead to the KV store?
No, shuffle sharding subrings are computed client-side and are not stored in the ring. KV store sizing still depends primarily on the number of replicas (of any component that uses the ring, e.g. ingesters) and tokens per replica.
However, each tenant’s subring is cached in memory on the client-side, which may slightly increase the memory footprint of certain components (mostly the distributor).