Distributed Query Execution
- Author: Harry John
- Date: June 2025
- Status: Proposed
Overview
Background
Cortex currently implements distributed query execution by rewriting queries into multiple subqueries, handled through middlewares in the query-frontend. These split queries are scheduled via the query-scheduler, evaluated by queriers, and merged back in the query-frontend. This proposal introduces a new distributed query execution model based on Thanos PromQL engine.
Terminology
- Logical plan - Parsed PromQL expression represented as a tree of logical operators.
- Query Plan - The logical query plan.
- Optimization - Selecting the most efficient logical plan.
- Planner/Optimizer - Component that performs optimization.
- Fragment - A portion of the query plan.
- Scheduling - Assigning fragments to queriers
Problem
Scalability
The current model struggles with high-cardinality queries scanning millions of series. Ingesters are not well-partitioned, and store-gateways don’t leverage partitioning during query execution. As a result, queriers often pull all data to a single node, creating bottlenecks.
Inefficient Merging
Merging results in the query-frontend—which isn’t shuffle-sharded — makes it a single point of failure. Poison queries with large responses can OOM all query-frontends, impacting availability.
Limited Query Rewriting
Today, queries are split via string manipulation. For example:
sum by (pod) (rate(http_req_total[5m])) over 2d
=> MERGE(sum by (pod) (rate(http_req_total{shard="1"}[5m])), sum by (pod) (rate(http_req_total{shard="2"}[5m])))
This is fragile and not scalable. Modern databases instead create a physical plan and split it into executable fragments assigned across nodes.
Lack of Optimizations
Cortex currently supports only basic optimizations (e.g., time and by/without clause-based splitting). Mature DBMS systems explore multiple execution strategies and pick the optimal one — something currently missing in Cortex.
Solution
Architecture Overview
This proposal introduces a new query execution model that will be implemented using the volcano-iterator model from the Thanos PromQL query engine. Here is a high level overview of the proposal of implementing query optimization and distributed query execution in Cortex:
- Query Frontend: Converts the logical plan into an optimized plan and sends the plan to the query-scheduler.
- Query Scheduler: Fragments the plan and assigns plan fragments to queriers.
- Queriers: Pull fragments, execute them, and return results. The root-fragment querier acts as coordinator, merging final results before notifying the frontend.
Query Frontend
The Query Frontend continues to act as the entry point for query_range and query APIs. The existing API layer is reused, but a new distributed query engine is introduced under the hood. This engine is responsible for generating and optimizing the query plan, and coordinating with the query scheduler.
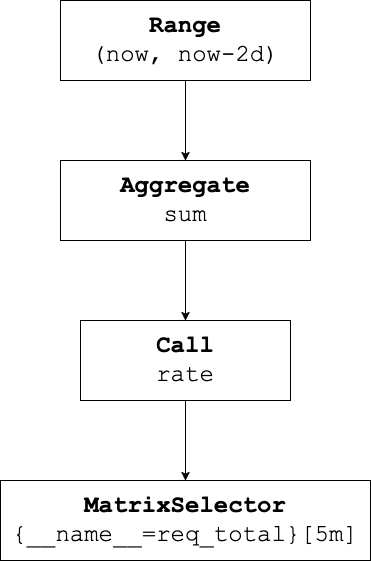
Logical Plan
When a query request is received, the PromQL expression is first parsed into a logical query plan, represented as a tree of logical operators. This logical plan is then passed through a series of optimizers that aim to transform the query into a more efficient structure. Consider the PromQL query sum(rate(req_total[5m])) to be run over 2 days. The query is parsed into the following basic logical plan.
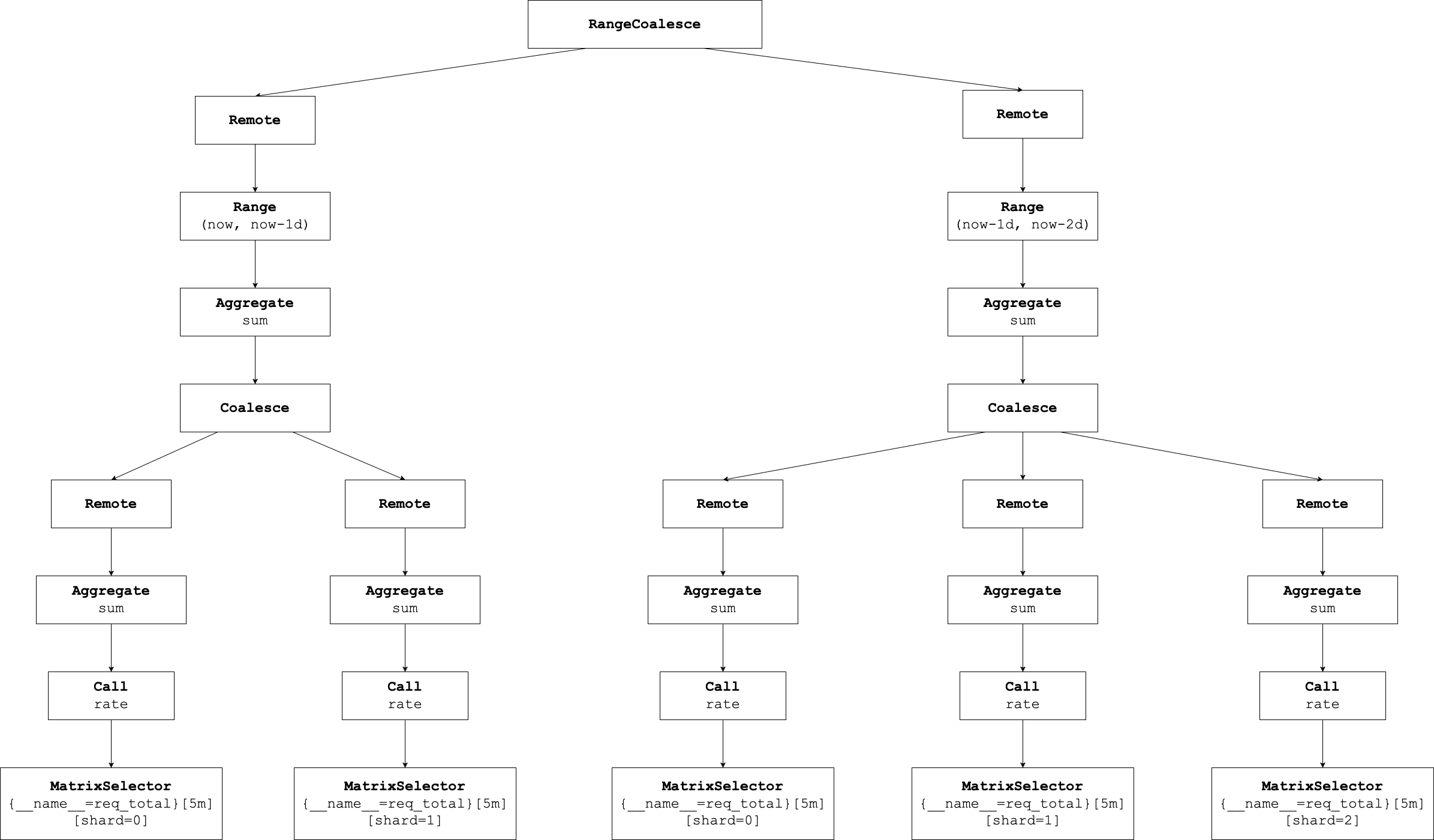
Distributed Optimizer
A special optimizer, the Distributed Optimizer, analyzes the logical plan to determine where and how the query can be split and executed in parallel. This is done by inserting Remote logical nodes at appropriate points in the plan tree.
These Remote nodes act as placeholders indicating plan fragments that can be offloaded to remote queriers. This enables sharding both over time and across data partitions.
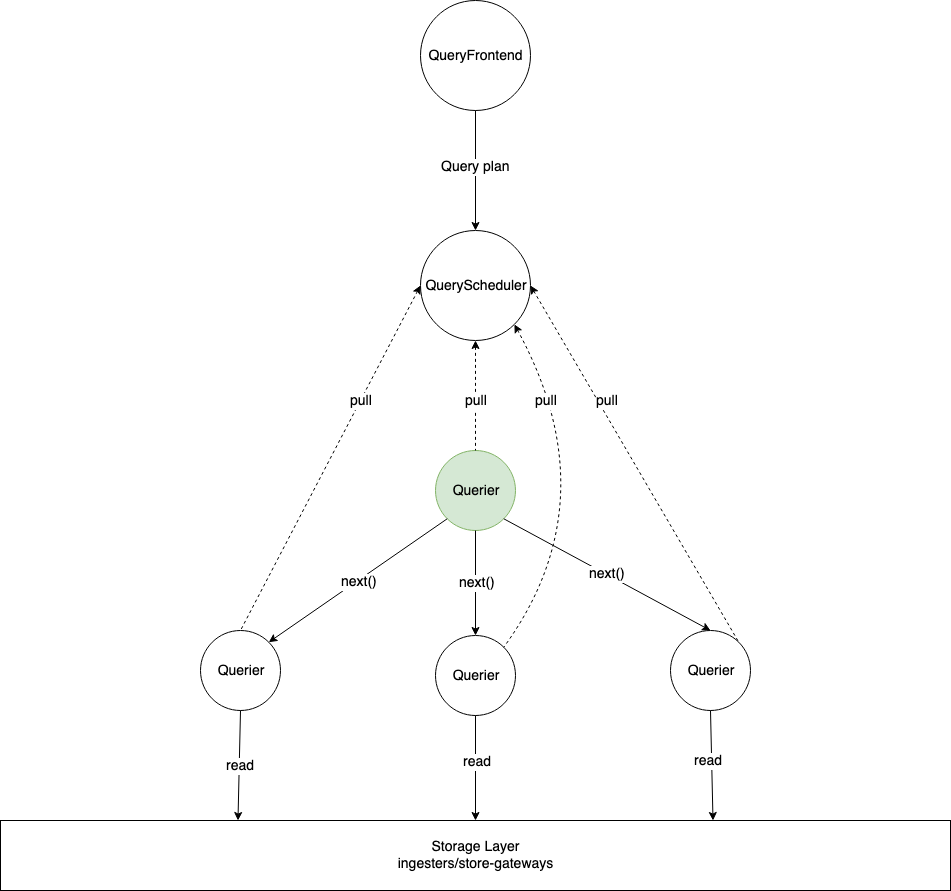
Query Scheduler
The Query Scheduler receives the optimized logical plan, including the Remote nodes introduced by the optimizer. It is responsible for fragmenting the plan and orchestrating its execution across multiple queriers.
Fragmentation
Fragmentation involves splitting the query plan into multiple fragments, where each fragment is a sub-tree of the overall plan that can be evaluated independently. Fragments are created by cutting the plan at Remote nodes. In the below diagram the coloured tiles mark the same fragment.
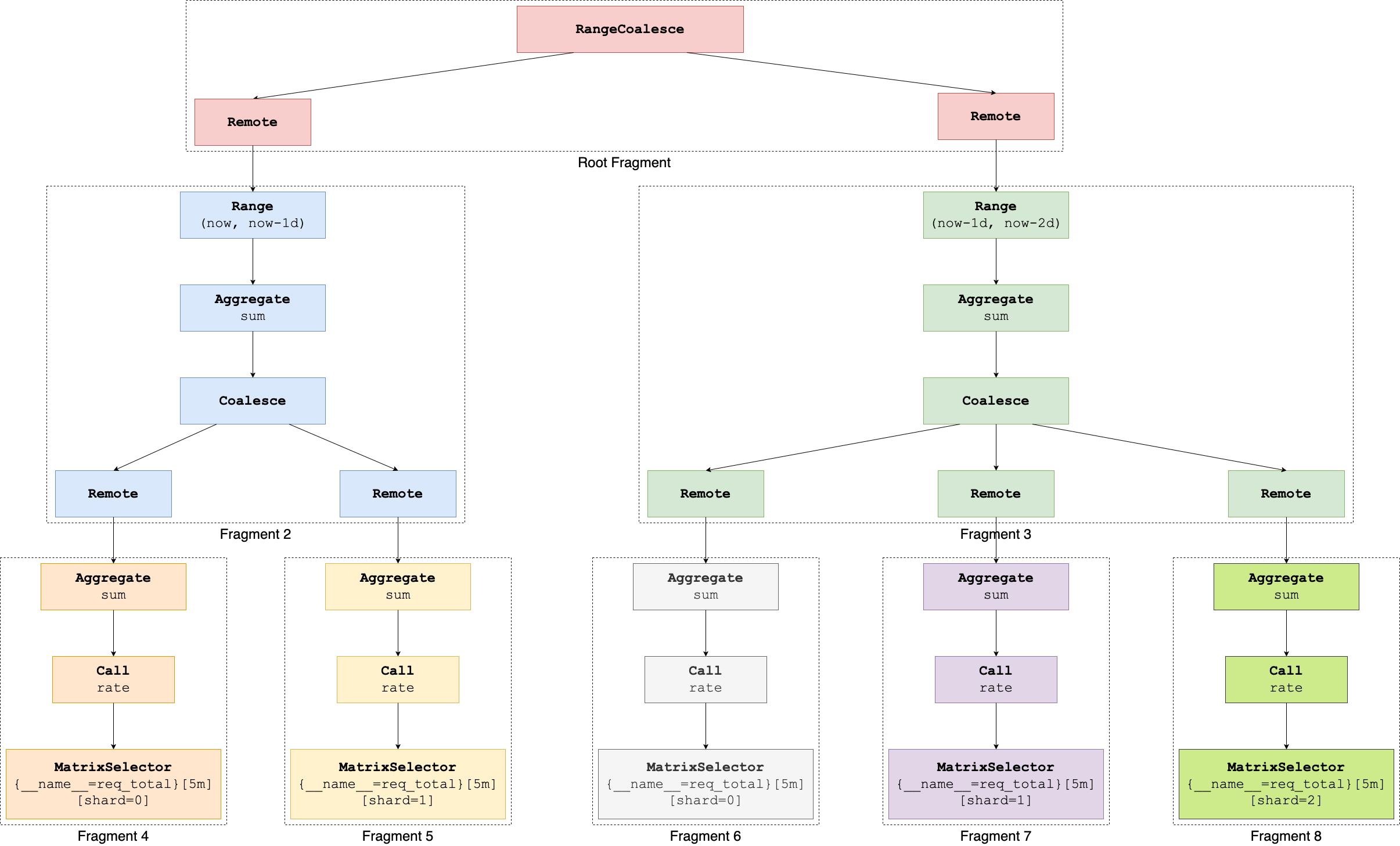
Enqueuing fragments
Fragmentation respects dependencies: child fragments are enqueued before parent fragments, ensuring data is available before dependent operations are scheduled. These fragments are then enqueued into the scheduler’s internal queue system, ready to be picked up by queriers.
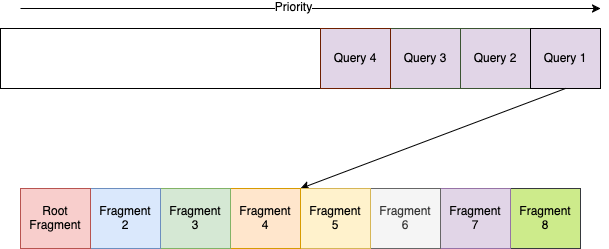
Assigning query fragments to queriers
The fragment include the plan and the remote fragment IDs it depends on. Queriers pull fragments from the scheduler. After child fragments are assigned to a particular querier, it’s parent fragment is updated with the location of the querier from which to read the results from.
At execution time, a Remote operator acts as a placeholder within the querier’s execution engine to pull results from other queriers running dependent fragments.
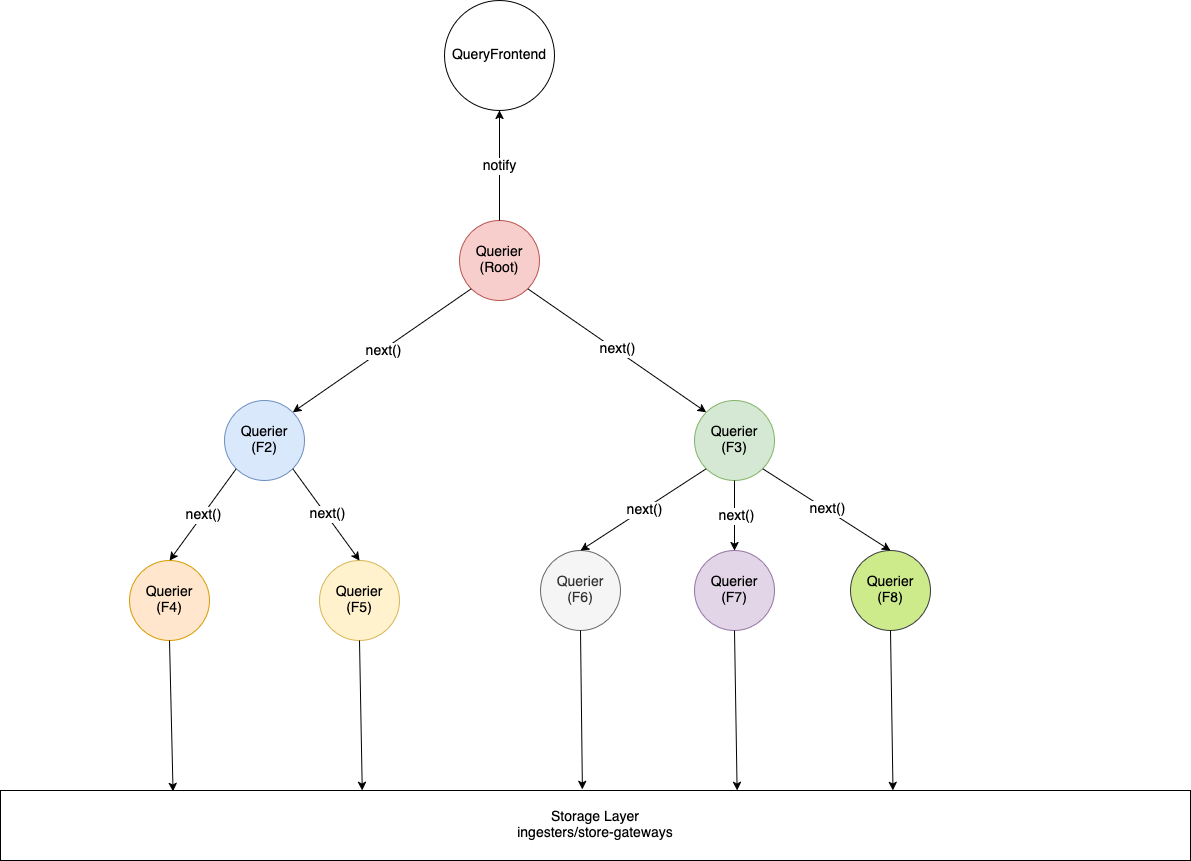
Querier
The Querier is enhanced to support both executing query fragments and serving results to other queriers. In the distributed query model, a querier may either evaluate a plan fragment or provide intermediate results to other queriers that depend on its output.
To support this, the querier now implements two interfaces:
- QueryExecutor – Executes assigned query plan root fragment.
- QueryServer – Serves results to other queriers via streaming gRPC endpoints. (i.e., acts as a remote data source for
Remoteoperators).
QueryExecutor
The QueryExecutor interface enables a querier to execute the root fragment of the distributed query plan.
type QueryExecutor interface {
ExecuteQuery(p LogicalPlan) (QueryResult, error)
}
QueryServer
The QueryServer interface enables a querier to expose query results to other queriers via a gRPC API. This is used when another querier is executing a fragment that depends on the results of this one (i.e., the child in the execution tree).
type QueryServer interface {
Enqueue(context.Context, p LogicalPlan) error
Series(SeriesRequest, querierpb.QueryServer_SeriesServer) error
Next(*executionpb.NextRequest, querierpb.QueryServer_NextServer) error
}
- Enqueue - Schedules the provided logical plan fragment for execution on the querier. Enqueuing a plan on a quereir will block a concurrency until the query finishes, or times out if it exceeds the configured limit. It respects the querier’s concurrency limits and queue capacity.
- Series - Streams the metadata (labels) for the series produced by the fragment, allowing parent queriers to understand the shape of incoming data.
- Next - Streams the actual step vector results of the fragment, returning time-step-wise computed samples and histograms.
These methods are implemented as streaming gRPC endpoints and used by Remote operators to pull data on-demand during execution.
gRPC Service Definition
service QueryServer {
rpc Series(SeriesRequest) returns (stream OneSeries);
rpc Next(NextRequest) returns (stream StepVectorBatch);
}
message OneSeries {
repeated Label labels = 1;
}
message StepVectorBatch {
repeated StepVector step_vectors = 1;
}
message StepVector {
int64 t = 1;
repeated uint64 sample_IDs = 2;
repeated double samples = 3;
repeated uint64 histogram_IDs = 4;
repeated FloatHistogram histograms = 5;
}
Together, the QueryExecutor and QueryServer roles allow each querier to act as both a compute node and a data provider, enabling true parallel and distributed evaluation of PromQL queries across Cortex’s infrastructure.
Fragment Execution
Each fragment is evaluated using the Thanos PromQL engine’s volcano iterator model, where operators are chained and lazily pulled for evaluation. If a fragment includes a RemoteOperator, it fetches the intermediate result from the peer querier serving the dependent fragment. Leaf operators such as MatrixSelector and VectorSelector read data from storage layer.
Co-ordinated Execution
The querier assigned the root fragment also plays the role of coordinator. The co-ordinator will
- Trigger dependent fragment execution by invoking Next() on the child queriers
- Wait for remote fragment results
- Assemble the final result
- Notify the QueryFrontend
This keeps the query execution tree distributed and parallelized, but the final result is merged and returned by a single coordinator node for consistency and simplicity.
Fallback
Not all types of queries are supported by Thanos PromQL engine. If any plan fragment is not supported by Thanos engine, the plan is converted back into a query string and evaluated by the Prometheus PromQL engine.
Error Handling
If any individual fragment fails or if a querier handling a fragment is restarted during execution, the entire query is considered failed. No retries or partial results are supported in the initial version. The root querier reports the error back to the QueryFrontend, which returns it to the client.
Conclusion
This proposal lays the groundwork for a robust and scalable distributed query execution in Cortex. By leveraging Thanos PromQL’s iterator engine and explicit fragmentation, it avoids string-based rewriting and unlocks deep query optimization and better fault isolation. Future iterations can explore support for retries, cost-based optimization, and fine-grained resource scheduling.