Parallel Compaction by Time Interval
- Author: Roy Chiang
- Date: May 2021
- Status: Proposed
Introduction
As a part of pushing Cortex’s scaling capability at AWS, we have done performance testing with Cortex and found the compactor to be one of the main limiting factors for higher active timeseries limit per tenant. The documentation Compactor describes the responsibilities of a compactor, and this proposal focuses on the limitations of the current compactor architecture. In the current architecture, compactor has simple sharding, meaning that a single tenant is sharded to a single compactor. The compactor generates compaction groups, which are groups of Prometheus TSDB blocks that can be compacted together, independently of another group. However, a compactor currently handles compaction groups of a single tenant iteratively, meaning that blocks belonging non-overlapping times are not compacted in parallel.
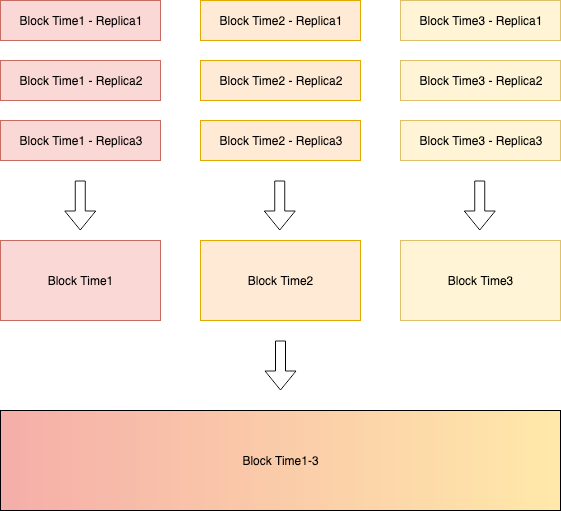
Cortex ingesters are responsible for uploading TSDB blocks with data emitted by a tenant. These blocks are considered as level-1 blocks, as they contain duplicate timeseries for the same time interval, depending on the replication factor. Vertical compaction is done to merge all the blocks with the same time interval and deduplicate the samples. These merged blocks are level-2 blocks. Subsequent compactions such as horizontal compaction can happen, further increasing the compaction level of the blocks.
Problem and Requirements
Currently, a compactor is able to compact up to 20M timeseries within 2 hours for a level-2 compaction, including the time to download blocks, compact, and upload the newly compacted block. We would like to increase the timeseries limit per tenant, and compaction is one of the limiting factors. In addition, we would like to achieve the following:
- Compact multiple non-overlapping time intervals concurrently, so we can achieve higher throughput for the compaction of a single tenant
- We should be able to scale up, down compactor as needed, depending on how many compactions are pending
- Insight into the compaction progress of a tenant, such as the number of compactions required in order to catch up to the newest blocks
Design
We accept the fact that a single compaction can potentially take more than 2 hours to compact, and we achieve higher compaction throughput through horizontally scaling the compactor. To compact more blocks in parallel for a single tenant, we distribute the compaction groups to compactors, instead of introducing more parallelism within a compactor.
Parallelize Work
This proposal builds heavily on top of the GrafanaLabs approach of introducing parallelism via time intervals. The difference being that a single tenant is now sharded across multiple compactors instead of just a single compactor. The initial approach will be to work on distinct time intervals, but the compactor planner can be later extended to introduce parallelism within a time interval as well.
The following is an example of parallelize work at each level:
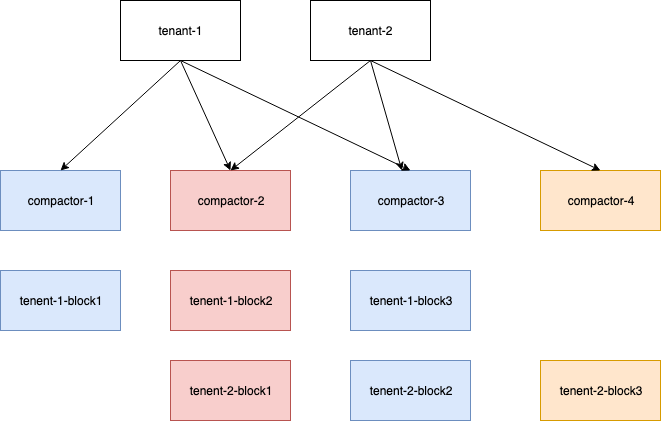
Compactors are shuffle-sharded, meaning that 1 tenant can belong to multiple compactors, and these subset of compactors determine which blocks should be compacted together. Compactors determine amongst themselves the responsibility of the compaction blocks, by using a hash of time interval and tenant id, and putting it on the sharding ring.
The benefit of this approach is that this aligns with what Cortex currently does in Ruler. The downside is that a compaction job can only be assigned to a single compactor, rather than all of the compactors sharded for the tenant. If a compaction job takes forever, other tenants sharded to the same compactor will be blocked until the issue is resolved. With the scheduler approach, any compactor assigned to a given tenant can pick up any work required.
Scenarios
Bad block resulting in non-ideal compaction groups
A Cortex operator configures the compaction block range as 2h and 6h. If a full 6-hour block cannot be compacted due to compaction failures, the compactor should not split up the group into subgroups, as this may cause suboptimal grouping of block. Cortex has full information regarding all the available blocks, so we should utilize this information to achieve the best compaction group possible.
Alternatives
Shard compaction jobs amongst compactors with a scheduler
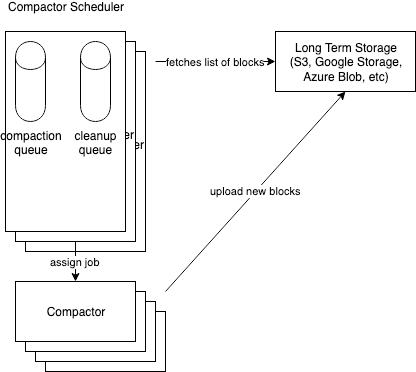
We add a new component Compactor Scheduler, which is responsible for calculating the compaction plan, and distributing compaction groups to compactors. The planner is sharded by tenant id, so that we can horizontally scale the planner as needed in order to accept more tenants in the cortex cluster. A tenant will have two queues inside the planner, a compaction queue and a clean up queue, similar to how the query frontend currently holds queues of pending queries.
Once a compactor scheduler pushes a job to a compactor, the job is no longer available. Every set interval, or once the compaction is done, a compactor will update the compactor schedule the current status of the compaction job. If a compactor does not provide an update to the scheduler within a timeout, the compaction job becomes available to be assigned to other compactors.
Concurrency
To achieve concurrency within a single tenant, compactor scheduler will push jobs to compactors. Compactors are shuffle-sharded by tenant id, to prevent a large tenant from impacting the compaction of other tenants. Compactor will download blocks from long term storage, compact, and upload. Compactor will also pull from the clean up queues from scheduler, and delete blocks marked for deletion.
Consistency
On resharding of compactor schedulers, a tenant might move to a different scheduler. We can either drop the current compactor job in order to prevent duplicate compaction jobs, or continue compaction. I propose that the compactor drops the compaction job if the compaction group no longer belongs to the original compactor scheduler. This way, we do not have duplicate compactions happening, and we can minimize work wasted.
Contribute to Thanos for a more scalable compactor
Instead of introducing parallelism on the Cortex compactor level, we move the parallelism to the Thanos compactor itself. Thanos has a proposal to make compactor more scalable, and a PR. Cortex will enjoy higher throughput per tenant if Thanos is able to speed up the compaction, and we can keep the Cortex architecture the same. However, this approach means that a single tenant is still sharded to a single compactor. In order to compact more groups at once, we must scale up compactor vertically. Although vertical scaling can get us far, we should scale horizontally where we can.