Scalable Alertmanager
- Author: Josh Abreu
- Date: December 2020
- Status: Accepted
Context and Background
The Cortex Alertmanager at its current state supports high-availability by using the same technique as the upstream Prometheus Alertmanager: we gossip silences and notifications between replicas to achieve eventual consistency. This allows us to tolerate machine failure without interruption of service. The caveat here is traffic between the ruler and Alertmanagers must not be load balanced as alerts themselves are not gossiped.
By itself it is not horizontally scalable; it is recommended to run a maximum of 3 replicas (for high availability). Each alertmanager replica will contain an internal instance for every tenant. The Alertmanager uses roughly ~3.7MB of memory and ~0.001 CPU cores per tenant, with an average tenant having ~10 active alerts and ~1 silences. These stats were measured from a cluster with ~80 QPS (Alerts received Per Second), ~40 NPS (Notifications Per Second), and ~700 configurations over a single replica.
Problem and Requirements
Current numbers show a reasonably sized machine can handle 2000 tenants in the current service. We would like to be able to scale this up to 10x without increasing the machine size; i.e. we would like to make Cortex Alertmanager service horizontally scalable.
Furthermore, we desire to preserve the following characteristics:
- A single Cortex Alertmanager replica crashing or exiting abruptly should not cause externally-visible downtime or failure to deliver notifications.
- Users should have an eventually consistent view of all the alerts current firing and under active notification, favouring availability of the Cortex Alertmanager over consistency.
- We should be able to scale up, down and roll out new versions of the service without any service interruption or data loss.
Design
This is a big design, and as such we have divided the problem up into 4 areas: Routing & Sharding, Persistence & State, Replication & Consistency, and Architecture. The options and solutions I propose are divided along these lines to aid clarity.
Routing & Sharding
To achieve horizontal scalability, we need to distribute the workload among replicas of the service. We need to choose an appropriate field to use to distribute the workload. The field must be present on all the API requests to the Alertmanager service.
We propose the sharding on Tenant ID. The simplicity of this implementation, would allow us to get up and running relatively quickly whilst helping us validate assumptions. We intend to use the existing ring code to manage this. Other options such as tenant ID + receiver or Tenant ID + route are relatively complex as distributor components (in this case the Ruler) would need to be aware of Alertmanager configuration.
Persistence & State
Alertmanager is a stateful service; it stores the notification state and configured silences. By default, Alertmanager persists its state to disk every 15mins. In the horizontally scalable Alertmanager service, we need to move this state around as the number of replicas grows and shrinks. We also need to persist this state across restarts and rolling upgrades.
We propose making each Alertmanager replica flush the state to object storage, under its own key that’s a combination of tenant ID + replica periodically. This state on durable storage will only be used when cold-starting the cluster.
This mechanism covers multiple challenges (scaling up & down, rolling restarts, total cluster failure). To top this off, in the implementation, we’ll always try to request state from other replicas in the cluster before ever trying to go to object storage.
Replication & Consistency
Upstream Alertmanager replicates notification state between replicas to ensure notifications are not sent more than once. Cortex Alertmanager does the same. When we move to a model where AM instances for a given tenant only live on a subset of replicas, we have to decide how we will keep these replicas in sync.
We have an option of doing nothing and use the existing gossip mechanism and gossip all tenants state to all replicas. The AM Router will then drop state updates for tenants which don’t shard to a given replica. I think this will be easy to implement as it requires few changes but probably won’t scale.
However, I propose we Synchronized state over gRPC. The upstream Alertmanager notification dispatcher uses a timeout-based approach for its notifications. Using the “peer order”, it’ll wait a certain amount of time before letting other replicas know if this notification succeeded or not. If it didn’t, the next replica in line will try to send the notification. We propose to communicate this via gRPC calls.
While I propose the use of gRPC, is good to note that doing nothing is still a solid candidate for consideration but not having to maintain and operate two separate replication patterns feels like a win.
Architecture
To implement the sharding strategy we need a component in charge of handling incoming alerts and API requests, distributing it to the corresponding shard.
The idea here is to have an “Alertmanager Distributor” as a first stop in the reception of alerts. Once alerts are received, the component is in charge of validating the alerts against the limits. Validated alerts are then sent to multiple managers in parallel.
The individual pieces of this component (sharding, limits) cannot be optional - the optional part of it is where we decide to run it.
We can either run it as a separate service or embed it. I propose we simply embed it. At its core it’ll be simpler to operate. With future work making it possible to run as a separate service so that operators can scale when/if needed.
Conclusion
Under the assumption we implement the options proposed above, our architecture looks like this:
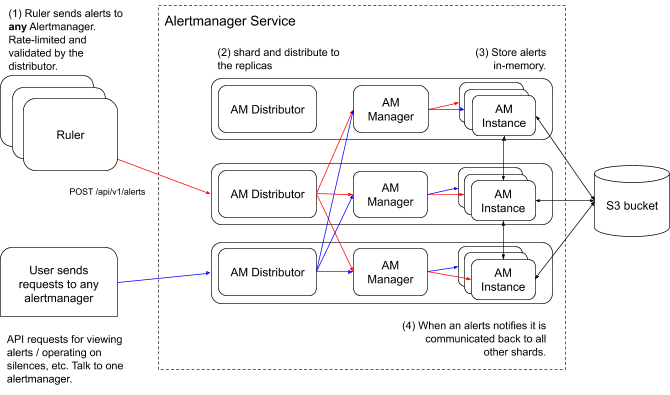
POST /api/v1/alerts (from the ruler) can go to any Alertmanager replica. The AM distributor uses the ring to write alerts to a quorum of AM managers (reusing the existing code). We continue to use the same in-memory data structure from the upstream Alertmanager to save alerts and notify other pieces
GET /api/v1/alerts and /api/v1/alerts/group uses the ring to find the right alertmanager replicas for the given tenant. They read from a quorum of alertmanager replicas and return an union of the results.
Alertmanager state is replicated between instances to keep them in sync. Where the state is replicated to to is controlled by the ring.